
Queue tables are used to take care of events. There is a mechanism that insert rows and another that takes care of the existing rows, usually deleting them at the end.
When possible one should use Oracle Advanced Queuing mechanism which takes care of managing the queue and a simple request will give you the next in the line.
Some applications develop their own queuing systems and it is a good way to learn how queue works.
Imagine a table with a list of elements and two specific columns:
- order of arrival
- priority
The first to be served is the one that, having the highest priority, was the first to arrive.
(It is not the fairest way to do it, as the ones with low priority might never be served. Ideally the priority should increase also with the wait time)
Problem
At my customer we have one of these selft designed queues. And it is responsible for the most consuming query:
UPDATE t_queue t1
SET begtime = SYSDATE,
id = 'xxxx',
clerk = 'yyy'
WHERE queue_tag = '*'
AND id IS NULL
AND order_of_arrival = (SELECT MIN(order_of_arrival)
FROM t_queue t2
WHERE t1.queue_tag = queue_tag
AND id IS NULL
AND retries < 10
AND priority = (SELECT MAX(priority)
FROM t_queue t3
WHERE queue_tag = '*'
AND id IS NULL
AND retries < 10));
So, the application tries to get, for any service (queue_tag), who was the first to arrive that has the highest priority.
The table has many columns, some of them quite large. The primary key is order_of_arrival.
First solution
So, in order to make the query faster, first I’ve created an index, avoiding to to read the whole table each time.
CREATE INDEX idx_t_queue_1 ON t_queue (queue_tag, id, retries, priority, order_of_arrival)
The execution plan, when the table has about 20% of rows matching the conditiongs (queue_tag and id) is:
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | UPDATE STATEMENT | | 1 | 14 | 235 (1)| 00:00:01 |
| 1 | UPDATE | T_QUEUE | | | | |
|* 2 | TABLE ACCESS BY INDEX ROWID| T_QUEUE | 1 | 14 | 2 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN | PK_T_QUEUE | 1 | | 1 (0)| 00:00:01 |
| 4 | SORT AGGREGATE | | 1 | 14 | | |
|* 5 | INDEX RANGE SCAN | IDX_T_QUEUE_1 | 4000 | 56000 | 116 (0)| 00:00:01 |
| 6 | SORT AGGREGATE | | 1 | 9 | | |
|* 7 | INDEX RANGE SCAN | IDX_T_QUEUE_1 | 19998 | 175K| 116 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
I wanted to make this query also simpler and beautiful. For this I turned to my Trivadis colleagues and specially to Kim Berg Hansen, writer of Pratical Oracle SQL book, who can make you to want to frame a SQL query on the wall. Kim suggested me this beautiful simple query:
UPDATE t_queue
SET begtime = SYSDATE,
id = 'xxx',
clerk = 'yyyy'
WHERE rowid = (
SELECT rowid FROM t_queue
WHERE queue_tag = '*'
AND id IS NULL
AND retries < 10
ORDER BY priority DESC, order_of_arrival
FETCH FIRST 1 ROW ONLY
);
The resulting execution plan was now reading only once the index:
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | UPDATE STATEMENT | | 1 | 26 | 119 (2)| 00:00:01 |
| 1 | UPDATE | T_QUEUE | | | | |
| 2 | TABLE ACCESS BY USER ROWID| T_QUEUE | 1 | 26 | 1 (0)| 00:00:01 |
|* 3 | VIEW | | 1 | 25 | 118 (2)| 00:00:01 |
|* 4 | WINDOW SORT PUSHED RANK | | 19998 | 507K| 118 (2)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | IDX_T_QUEUE_1 | 19998 | 507K| 116 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Interesting enough, when testing 1000 consecutive runs, the original query was faster than the FETCH FIRST ROW version:
- Time subqueries: 11,15 s
- Time fetch first: 12,23 s
But this was only when there were >10% of rows matching the conditions. If there are <10% of rows where it needs to find the first one, then the FETCH FIRST ROW is faster.
Kim Berg Hansen’ solution
Kim did some more investigation and asked me to test with two other indexes, which would force a better execution plan. First:
CREATE INDEX t_myqueue_idx_fnc_asc ON t_queue (
queue_tag, CASE WHEN id IS NULL THEN 1 END, CASE WHEN retries < 10 THEN 1 END, priority, order_of_arrival
);
As this is a function based index, the queries needed to be changed to make use of it. The new queries would be:
UPDATE t_queue q1
SET begtime = SYSDATE,
id = 'xxx',
clerk = 'yyyy'
WHERE q1.order_of_arrival = (
SELECT MIN(q2.order_of_arrival)
FROM t_queue q2
WHERE q2.queue_tag = '*'
AND CASE WHEN q2.id IS NULL THEN 1 END = 1
AND CASE WHEN q2.retries < 10 THEN 1 END = 1
AND q2.priority = (
SELECT MAX(q3.priority)
FROM t_queue q3
WHERE q3.queue_tag = '*'
AND CASE WHEN q3.id IS NULL THEN 1 END = 1
AND CASE WHEN q3.retries < 10 THEN 1 END = 1
)
);
resulting on execution plan:
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows |Bytes |Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------------
| 0 | UPDATE STATEMENT | | 1 | 14 | 8 (0)| 00:00:01 |
| 1 | UPDATE | T_QUEUE | | | | |
| 2 | TABLE ACCESS BY INDEX ROWID | T_QUEUE | 1 | 14 | 2 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN | PK_T_QUEUE | 1 | | 1 (0)| 00:00:01 |
| 4 | SORT AGGREGATE | | 1 | 15 | | |
| 5 | FIRST ROW | | 1 | 15 | 3 (0)| 00:00:01 |
|* 6 | INDEX RANGE SCAN (MIN/MAX) | T_MYQUEUE_IDX_FNC_ASC | 1 | 15 | 3 (0)| 00:00:01 |
| 7 | SORT AGGREGATE | | 1 | 10 | | |
| 8 | FIRST ROW | | 1 | 10 | 3 (0)| 00:00:01 |
|* 9 | INDEX RANGE SCAN (MIN/MAX)| T_MYQUEUE_IDX_FNC_ASC | 1 | 10 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------------
and
UPDATE t_queue q1
SET begtime = SYSDATE,
id = 'xxx',
clerk = 'yyyy'
WHERE q1.rowid = (
SELECT rowid
FROM t_queue
WHERE queue_tag = '*'
AND CASE WHEN id IS NULL THEN 1 END = 1
AND CASE WHEN retries < 10 THEN 1 END = 1
ORDER BY queue_tag, CASE WHEN id IS NULL THEN 1 END, CASE WHEN retries < 10 THEN 1 END, priority DESC, order_of_arrival
FETCH FIRST 1 ROW ONLY
);
With execution plan:
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------
| 0 | UPDATE STATEMENT | | 1 | 26 | 55 (4)| 00:00:01 |
| 1 | UPDATE | T_QUEUE | | | | |
| 2 | TABLE ACCESS BY USER ROWID| T_QUEUE | 1 | 26 | 1 (0)| 00:00:01 |
|* 3 | VIEW | | 1 | 25 | 54 (4)| 00:00:01 |
|* 4 | WINDOW SORT PUSHED RANK | | 11991 | 316K| 54 (4)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | T_MYQUEUE_IDX_FNC_ASC | 11991 | 316K| 52 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------
The time with subqueries was now using INDEX RANGE SCAN(MIN/MAX) and was incredibly faster, while FETCH FIRST was still using WINDOWS SORT PUSHED RANK and the timing did not change:
- Time subqueries: 0,57 seconds (any % of matching rows)
- Time fetch first: 12,88 seconds (20% matching rows)
- Time fetch first: 7,54 (10% matching rows)
The other index, with priority column in different order, would be:
CREATE INDEX t_myqueue_idx_fnc_dsc ON t_queue (
queue_tag, CASE WHEN id IS NULL THEN 1 END, CASE WHEN retries < 10 THEN 1 END, priority DESC, order_of_arrival
);
Which resulted in this execution plan back to INDEX RANGE SCAN for the subqueries version:
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------------
| 0 | UPDATE STATEMENT | | 1 | 14 | 149 (0)| 00:00:01 |
| 1 | UPDATE | T_QUEUE | | | | |
| 2 | TABLE ACCESS BY INDEX ROWID| T_QUEUE | 1 | 14 | 2 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN | PK_T_QUEUE | 1 | | 1 (0)| 00:00:01 |
| 4 | SORT AGGREGATE | | 1 | 15 | | |
|* 5 | INDEX RANGE SCAN | T_MYQUEUE_IDX_FNC_DSC | 3999 | 59985 | 26 (0)| 00:00:01 |
| 6 | SORT AGGREGATE | | 1 | 10 | | |
|* 7 | INDEX RANGE SCAN | T_MYQUEUE_IDX_FNC_DSC | 19996 | 195K| 121 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------------
and with FETCH FIRST version, a new plan now using WINDOW BUFFER PUSHED RANK:
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------------
| 0 | UPDATE STATEMENT | | 1 | 26 | 122 (0)| 00:00:01 |
| 1 | UPDATE | T_QUEUE | | | | |
| 2 | TABLE ACCESS BY USER ROWID | T_QUEUE | 1 | 26 | 1 (0)| 00:00:01 |
|* 3 | VIEW | | 1 | 25 | 121 (0)| 00:00:01 |
|* 4 | WINDOW BUFFER PUSHED RANK| | 19996 | 527K| 121 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | T_MYQUEUE_IDX_FNC_DSC | 19996 | 527K| 121 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------------
In this case the results were:
- Time subqueries: 8,01 (20% matching rows)
- Time fetch first: 10,89 (20% matching rows)
- Time subqueries: 3,84 (10% matching rows)
- Time fetch first: 5,18 (10% matching rows)
Addendum – Mikhail Velikikh suggestion
Mikhail Velikikh quickly commented to this post, warning me about an error on a query in the post (thanks!) and, using the descending function based index, suggested a more beautiful solution:
update t_myqueue q1
set id = 'x'
where q1.rowid = (
select * from (
select rowid
from t_myqueue
where queue_tag = '*'
and case when id is null then 1 end = 1
and case when retrycount < 10 then 1 end = 1
order by queue_tag, case when id is null then 1 end, case when retrycount < 10 then 1 end, priority desc, order_of_arrival
)
where rownum=1 );
Indeed at the first tests, Mikhail’ solution become the fastest when his query was run immediately after the index creation – doing a range scan and stop count, with 0.3 seconds. In most of the cases, as I did not run immediately this test case, then it becomes slow as it does a fast full scan.
Final results
We have now:
- One table with 100k rows
- PK is a sequence related to order of arrival
- There is a priority column
- 3 possible indexes – one simple composite, two function based: ascending and descending
- 3 amount of matching rows – 10%, 20% and 100%
- 6 different update queries – one set for the simple index: using subqueries, using fetch first, using stop count; another set for the function based indexes, also the three different forms: subqueries, fetch first and stop count.
I’ve run more than 5 times a procedure that executes 1000 times the same update query and check how long it took. In the table and graph below I’ve always used the best result of each of the runs. Note: the results are better than on the text of the blog above, as I’ve now done much more runs and assured each time there was only one index on the table, apart of the primary key.
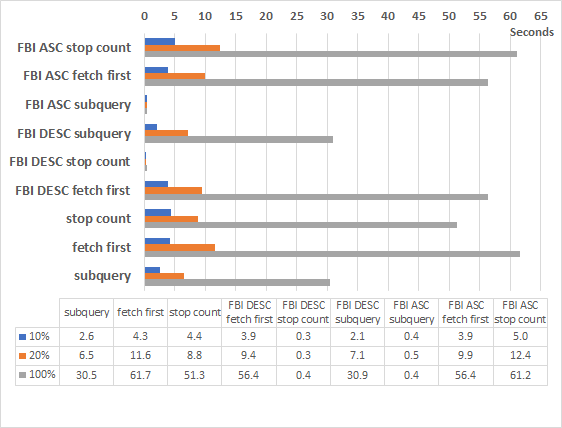
Conclusion
When possible, and if a query like this really needs to be improved, it is good idea to try using a function based index and changing the query code. It will not look so nicely, though.
With an FBI ascending index, and subqueries we get INDEX RANGE SCAN (MIN/MAX) access. The speed of the query was constantly impressively fast: ~0,5 seconds for 1000 executions, in any situation.
With an FBI descending index, a bit nicer looking query with INDEX RANGE SCAN and STOP COUNT access. The speed was impressive, at ~0,3 or ~0.4 seconds. Unfortunately this great execution plan was not always chosen by the optimizer, mainly when the query was not immediately run after the index creation (did have then some fragmentation?). In that case was doing INDEX FAST FULL SCAN and performance was on the dozens of seconds.
When you don’t want to use function based index because it will likely not be used by any other query, then the best solution was the subqueries version of the SQL, at least 40% faster than the other SQL versions.
A big thanks to Kim Berg Hansen for all his help and insights and to Mikhail Velikikh for the new suggestion.
Test case
In case you want to test at your own lab, below you can find the complete test case.
/* Create Queue table */
drop table t_myqueue purge;
create table t_myqueue (
order_of_arrival number
, priority number not null
, retrycount number default 0 not null
, queue_tag varchar2(1000) default '*' not null
, id varchar2(64)
, filler1 varchar2(1000)
, filler2 varchar2(1000)
, CONSTRAINT pk_t_myqueue PRIMARY KEY (order_of_arrival)
);
/* Create indexes (choose one) */
DROP INDEX idx_t_myqueue_1;
DROP INDEX idx_t_myqueue_fbi_asc;
DROP INDEX idx_t_myqueue_fbi_dsc;
CREATE INDEX idx_t_myqueue_1 ON t_myqueue (queue_tag, id, priority, retrycount, order_of_arrival);
CREATE INDEX idx_t_myqueue_fbi_asc ON t_myqueue (
queue_tag, CASE WHEN id IS NULL THEN 1 END, CASE WHEN retrycount < 10 THEN 1 END, priority, order_of_arrival
);
CREATE INDEX idx_t_myqueue_fbi_dsc ON t_myqueue (
queue_tag, CASE WHEN id IS NULL THEN 1 END, CASE WHEN retrycount < 10 THEN 1 END, priority DESC, order_of_arrival
);
/* Clear, fill table, gather stats - uncomment one line */
truncate table t_myqueue;
insert into t_myqueue
select level as order_of_arrival,
floor(dbms_random.value(1, 6)) as priority,
0 as retrycount,
'*' queue_tag,
-- /* 100% matches */ null as id,
-- /* 20% matches */ case when mod(rownum, 5)=0 then null else sys_guid() end as id,
/* 10% matches */ case when mod(rownum, 10)=0 then null else sys_guid() end as id,
rpad('xxhx',1000,'xder') as filler1,
rpad('xdsxx',1000,'xgdder') as filler2
from dual
connect by level <=100000;
commit;
exec dbms_stats.gather_table_stats(user,'t_myqueue');
/* Create testing procedure */
CREATE OR REPLACE PROCEDURE time_sql_x (title varchar2, sqltxt varchar2) AS
timestart INTEGER;
counter INTEGER;
BEGIN
dbms_output.enable;
timestart := dbms_utility.get_time();
FOR counter IN 1..1000
LOOP
execute immediate(sqltxt);
END LOOP;
dbms_output.put_line(title||': ' || to_char((dbms_utility.get_time() - timestart)/100,'0.99') || ' seconds');
rollback;
END;
/
/* Enable output */
set server output on;
/* Check table matches */
select total, matches, to_char(matches/total*100 ||'%') PCT from (
select count(*) total, count(case when id is null and queue_tag='*' and retrycount<10 then 1 end) matches from t_myqueue);
/* Run tests */
begin time_sql_x('Simple subqueries',q'[
update t_myqueue q1
set id = 'x'
where q1.order_of_arrival = (
select min(q2.order_of_arrival)
from t_myqueue q2
where q2.queue_tag = '*'
and q2.id is null
and q2.retrycount < 10
and q2.priority = (
select max(q3.priority)
from t_myqueue q3
where q3.queue_tag = '*'
and q3.id is null
and q3.retrycount < 10
)
)
]'); end;
/
begin time_sql_x('Simple fetch first',q'[
update t_myqueue q1
set id = 'x'
where q1.rowid = (
select rowid
from t_myqueue
where queue_tag = '*'
and id is null
and retrycount < 10
order by priority desc, order_of_arrival
fetch first 1 row only
)
]'); end;
/
begin time_sql_x('Simple Stop count',q'[
update t_myqueue q1
set id = 'x'
where q1.rowid = (
select * from (
select rowid
from t_myqueue
where queue_tag = '*'
and id is null
and retrycount < 10
order by priority desc, order_of_arrival
)
where rownum=1
)
]'); end;
/
begin time_sql_x('FBI - Subqueries',q'[
update t_myqueue q1
set id = 'x'
where q1.order_of_arrival = (
select min(q2.order_of_arrival)
from t_myqueue q2
where q2.queue_tag = '*'
and case when q2.id is null then 1 end = 1
and case when q2.retrycount < 10 then 1 end = 1
and q2.priority = (
select max(q3.priority)
from t_myqueue q3
where q3.queue_tag = '*'
and case when q3.id is null then 1 end = 1
and case when q3.retrycount < 10 then 1 end = 1
)
)
]'); end;
/
begin time_sql_x('FBI - Fetch First',q'[
update t_myqueue q1
set id = 'x'
where q1.rowid = (
select rowid
from t_myqueue
where queue_tag = '*'
and case when id is null then 1 end = 1
and case when retrycount < 10 then 1 end = 1
order by queue_tag, case when id is null then 1 end, case when retrycount < 10 then 1 end, priority desc, order_of_arrival
fetch first 1 row only
)
]'); end;
/
begin time_sql_x('FBI - Stop count',q'[
update t_myqueue q1
set id = 'x'
where q1.rowid = (
select * from (
select rowid
from t_myqueue
where queue_tag = '*'
and case when id is null then 1 end = 1
and case when retrycount < 10 then 1 end = 1
order by queue_tag, case when id is null then 1 end, case when retrycount < 10 then 1 end, priority desc, order_of_arrival
)
where rownum=1
)
]'); end;
/
Hi Anjo,
That is the query you provided in the post:
UPDATE t_queue q1
SET begtime = SYSDATE,
id = ‘xxx’,
clerk = ‘yyyy’
WHERE q1.order_of_arrival = (
SELECT MIN(q2.order_of_arrival)
FROM t_queue q2
WHERE q2.queue_tag = ‘*’
AND CASE WHEN q2.id IS NULL THEN 1 END = 1
AND CASE WHEN q2.retries < 10 THEN 1 END = 1
AND q2.priority = (
SELECT MAX(q3.priority)
FROM t_queue q3
WHERE q3.queue_tag = '*'
AND CASE WHEN q2.id IS NULL THEN 1 END = 1
AND CASE WHEN q2.retries < 10 THEN 1 END = 1
)
);
I do not think that that query can have the execution plan you provided with INDEX RANGE SCAN (MIN/MAX).
The max(priority) subquery should have had 'CASE WHEN q3.id IS NULL' conditions rather than 'CASE WHEN q2.id IS NULL'..
Regards,
Mikhail.
Hi Mikhail,
Thanks a lot for spotting it. It was a copy/paste problem to WordPress. It is corrected now.
Cheers,
Miguel Anjo
Hi Anjo,
I tried to model some queries using that little data you provided.
In order to use the descending index, I would rewrite the query as follows:
UPDATE t_queue q1
SET begtime = SYSDATE,
id = ‘xxx’,
clerk = ‘yyyy’
WHERE q1.rowid = (
select * from (
SELECT /*+ index(t_queue t_myqueue_idx_fnc_dsc)*/rowid
FROM t_queue
WHERE queue_tag = ‘*’
AND CASE WHEN id IS NULL THEN 1 END = 1
AND CASE WHEN retries < 10 THEN 1 END = 1
ORDER BY queue_tag, CASE WHEN id IS NULL THEN 1 END, CASE WHEN retries ‘alias outline projection’);
Here is its execution plan:
—————————————————————————————————–
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
—————————————————————————————————–
| 0 | UPDATE STATEMENT | | 1 | 101 | 2 (50)| 00:00:01 |
| 1 | UPDATE | T_QUEUE | | | | |
| 2 | TABLE ACCESS BY USER ROWID| T_QUEUE | 1 | 101 | 1 (0)| 00:00:01 |
|* 3 | COUNT STOPKEY | | | | | |
| 4 | VIEW | | 1 | 12 | 1 (100)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | T_MYQUEUE_IDX_FNC_DSC | 1 | 51 | 0 (0)| 00:00:01 |
—————————————————————————————————–
Predicate Information (identified by operation id):
—————————————————
3 – filter(ROWNUM=1)
5 – access(“QUEUE_TAG”=’*’ AND CASE WHEN “ID” IS NULL THEN 1 END =1 AND CASE WHEN
“RETRIES”<10 THEN 1 END =1)
It is worth noting that it has a COUNT STOPKEY operation and does not have any SORT operations.
Besides, it has less buffer gets than your query with two MIN/MAX subqueries.
Those queue_tag, case when.. conditions are mentioned only once – the DRY principle which I encourage at my shop – there is less chance of making a mistake while editing the query.
As a little fringe benefit, it has fewer lines in the execution plan – a pleasure to read it.
Regards,
Mikhail.
Hi again Mikhail,
Great, I will definitely try the solution you suggest. It seems promising.
Today I’ll not be working, but hopefully I’ll find a moment tomorrow to post the results.
I’ll also copy here the complete test case, so people don’t have to recreate their own.
Thanks again,
Miguel Anjo
Hi Miguel,
I initially addressed you as ‘Anjo’ since I thought it was Anjo Kolk’s website. Sorry for my mistake.
You wrote:
I provided my query with a certain hint to force a specific execution plan.
I see that you decided to remove that hint in your ‘FBI – Stop count’ test.
The following block is the fastest on 19.7 in terms of buffer gets and elapsed time per execution.
Does it perform differently in your environment?
begin time_sql_x('FBI - Stop count',q'[ update t_myqueue q1 set id = 'x' where q1.rowid = ( select * from ( select /*+ index(t_myqueue idx_t_myqueue_fbi_dsc)*/rowid from t_myqueue where queue_tag = '*' and case when id is null then 1 end = 1 and case when retrycount < 10 then 1 end = 1 order by queue_tag, case when id is null then 1 end, case when retrycount < 10 then 1 end, priority desc, order_of_arrival ) where rownum=1); select sql_id, buffer_gets/executions lio, elapsed_time/executions ela, sql_text from v$sqlarea where sql_text like '%update t_myqueue%' and executions=1000 order by lio; SQL_ID LIO ELA SQL_TEXT ------------- ---------- ---------- ---------------------------------------------------------------------------------------------------- bc31mt9cdzya1 25.132 89.628 update t_myqueue q1 set id = 'x' where q1.rowid = ( select * from ( select /*+ index(t_myqueue idx_t_myqueue_fbi_dsc)*/ rowid from t_myqueue where queue_tag = '*' and case when id is null then 1 end = 1 and case when retrycount < 10 then 1 end = 1 order by queue_tag, case when id is null then 1 end, case when retrycount < 10 then 1 end, priority desc, order_of_arrival ) where rownum=1 ) 28ahw0udp3v2b 31.641 116.093 update t_myqueue q1 set id = 'x' where q1.order_of_arrival = ( select min(q2.order_of_arrival) from t_myqueue q2 where q2.queue_tag = '*' and case when q2.id is null then 1 end = 1 and case when q2.retrycount < 10 then 1 end = 1 and q2.priority = ( select max(q3.priority) from t_myqueue q3 where q3.queue_tag = '*' and case when q3.id is null then 1 end = 1 and case when q3.retrycount < 10 then 1 end, priority desc, order_of_arrival ) where rownum=1 )When you don’t want to use function based index because it will likely not be used by any other query, then the best solution was the subqueries version of the SQL, at least 40% faster than the other SQL versions.
Regards,
Mikhail.
Hi Mikhail,
I would prefer not to use hints, that is why I did remove from the test case you provided.
As soon as I can I’ll do the test with the hint and update the post in case there is more information.
I would like to post also the results of autotrace for each of the solutions, but no time yet.
Thanks for following it up!
PS: I tried to improve the format of your last reply. Let me know in case I introduce errors.
Hi Miguel,
I have noticed that the formatting gets broken. Is there any specific character/string breaking it?
> I would prefer not to use hints, that is why I did remove from the test case you provided.
I would keep that hint in this case since CBO considers other indexes cheaper for that update because they have less leaf blocks.
I slightly modified your script to include the test name in the comment to the update statement, so that it becomes easy to differentiate those queries in the TKPROF output:
https://github.com/mvelikikh/oracle/blob/master/blog/202006_miguel_anjo_update_queue_table_with_priorities/update_queue_with_priorities.sql
That is the spool file I got after running this script in a 19.7 database:
https://github.com/mvelikikh/oracle/blob/master/blog/202006_miguel_anjo_update_queue_table_with_priorities/update_queue_with_priorities.lst
That output shows that the FBI – Subqueries test took 0.53 seconds:
FBI – Subqueries: 0.53 seconds
Whereas the update that I proposed took just 0.34 seconds:
FBI – Stop count: 0.34 seconds
The raw trace file in addition to the TKPROF processed one are available in the same GitHub folder:
https://github.com/mvelikikh/oracle/blob/master/blog/202006_miguel_anjo_update_queue_table_with_priorities/update_queue_with_priorities.tkp
We can clearly see from that TKPROF file that the FBI – Stop Count update performs 5855 consistent gets and 19204 current gets per 1000 executions.
The solution you named the best, which is FBI – Subqueries, performs 12250 consistent gets and 19222 current gets per the same number of executions.
Unsurprisingly, the number of current gets is the same – we update the same rows and indexes. However, the number of consistents gets is different, as well as the update’s elapsed time: it’s 0.17 seconds for FBI – Stop Count vs 0.25 seconds for FBI – Subqueries.
Based on all that data I provided, I can say that FBI – Stop Count is the most performant solution in terms of consistent gets and elapsed time for this specific case with 10% of rows. I think that the conclusion you made is a bit inaccurate.
Are you getting different results?