Copy Audit and unified audit across databases
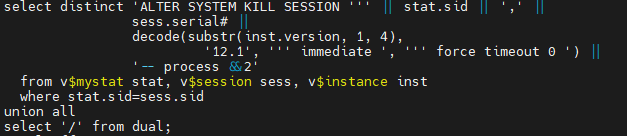
The client had a special request: copy the audit data to another database – once -, for compliance reasons.
The Audit data does not let it copy so easily. Before was usually in SYS schema, now it belongs to a special AUDSYS user. None allows to export data by default.
To copy the audit data from one database to another, there is special expdp argument: “include=audit_trails”. This only works in full export mode:
expdp system@server.domain.ch\pdb_service \
DIRECTORY=expdp \
DUMPFILE=audit_data_$(date +%Y%m%d_%H%M).dmp \
FULL=Y \
INCLUDE=AUDIT_TRAILS
On the new database, I’ve imported to a new user “old_audit” and specific tablespace, which I created before the import
SYS@DB1.PDB1> create tablespace unified_audit_ts;
SYS@DB1.PDB1> alter user system quota unlimited on unified_audit_ts;
SYS@DB1.PDB1> create user old_audit no authentication
default tablespace unified_audit_ts
quota unlimited on unified_audit_ts;
At the end I’ve imported the data, using remap_schema and remove the segment attributes, so all go to the new default tablespace:
impdp system@server.domain.ch\new_pdb \
DIRECTORY=expdp
DUMPFILE=$(ls -tr audit_data*.dmp | tail -n1)
REMAP_SCHEMA=sys:old_audit
REMAP_SCHEMA=audsys:old_audit
TRANSFORM=SEGMENT_ATTRIBUTES:N